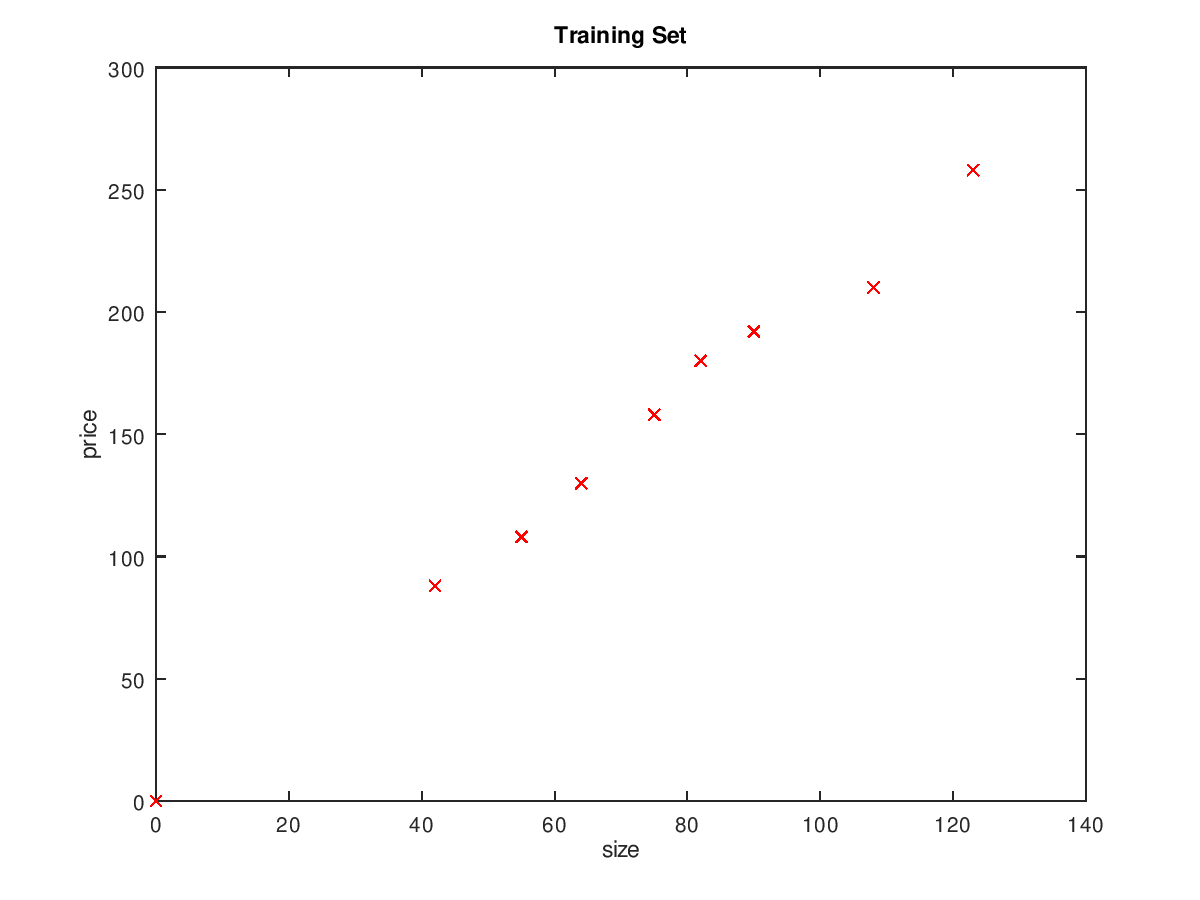
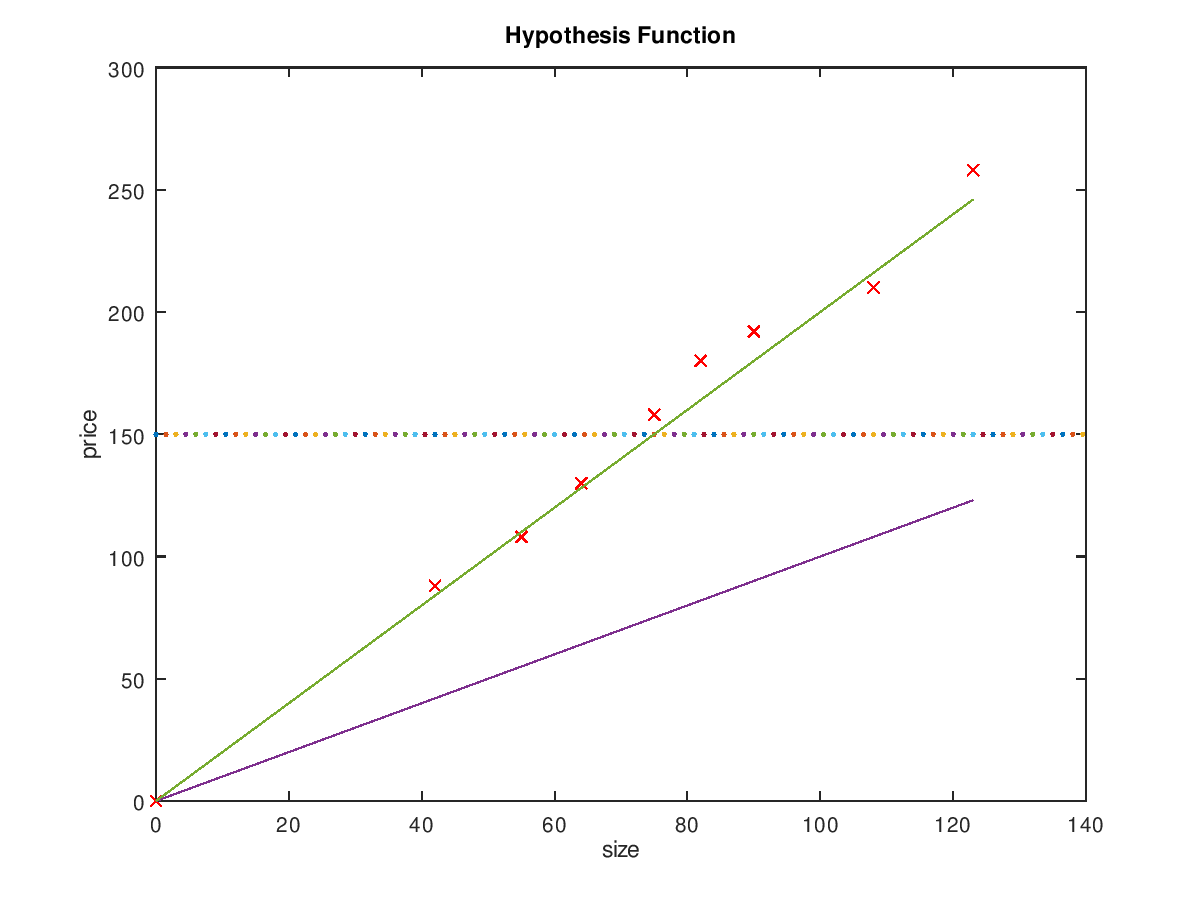
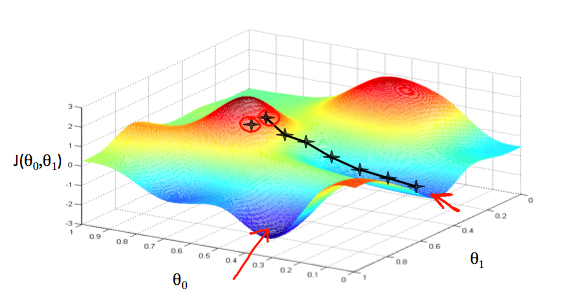
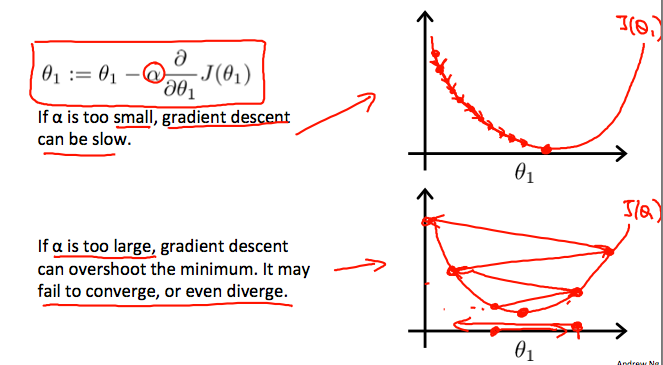
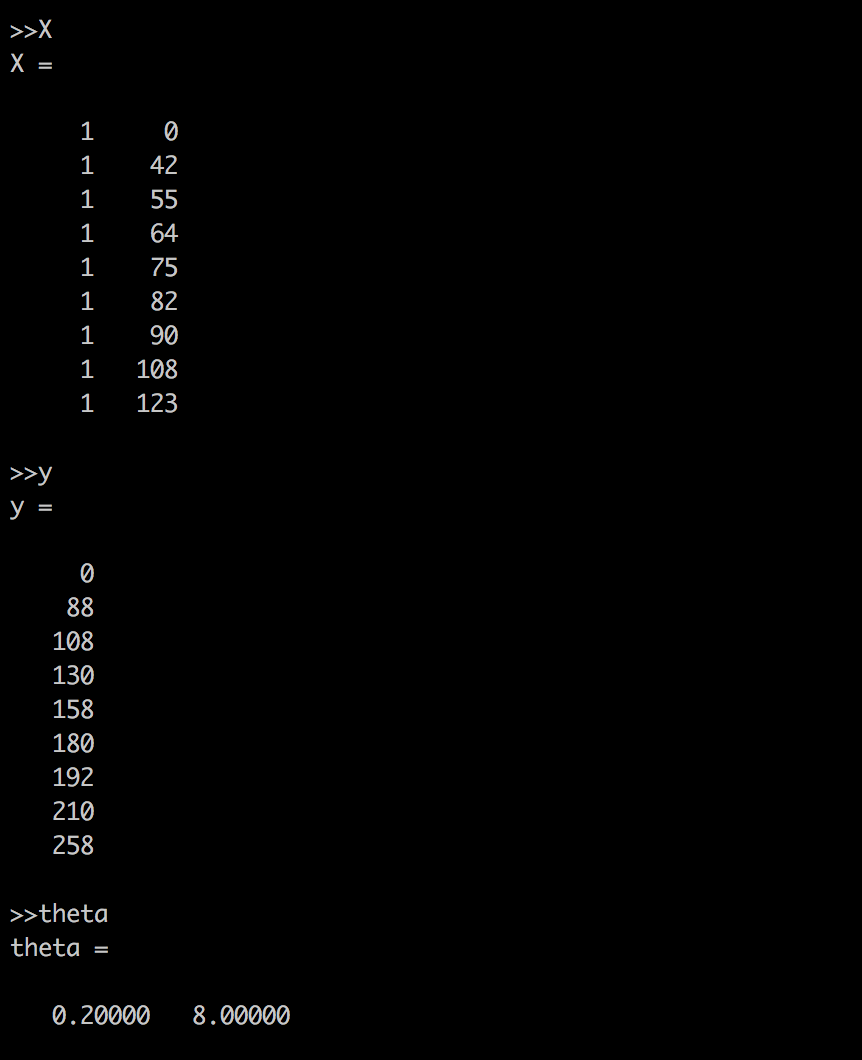
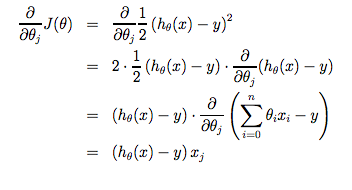function J = computeCost(X, y, theta) %COMPUTECOST Compute cost for linear regression % J = COMPUTECOST(X, y, theta) computes the cost of using theta as the % parameter for linear regression to fit the data points in X and y
% Initialize some useful values m = length(y); % number of training examples
% You need to return the following variables correctly J = 0;
% ====================== YOUR CODE HERE ====================== % Instructions: Compute the cost of a particular choice of theta % You should set J to the cost.
m = size(X,1); predictions = X*theta; sqrErrors = (predictions-y).^2;
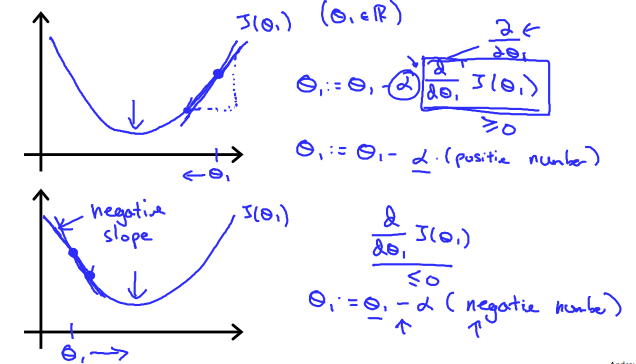
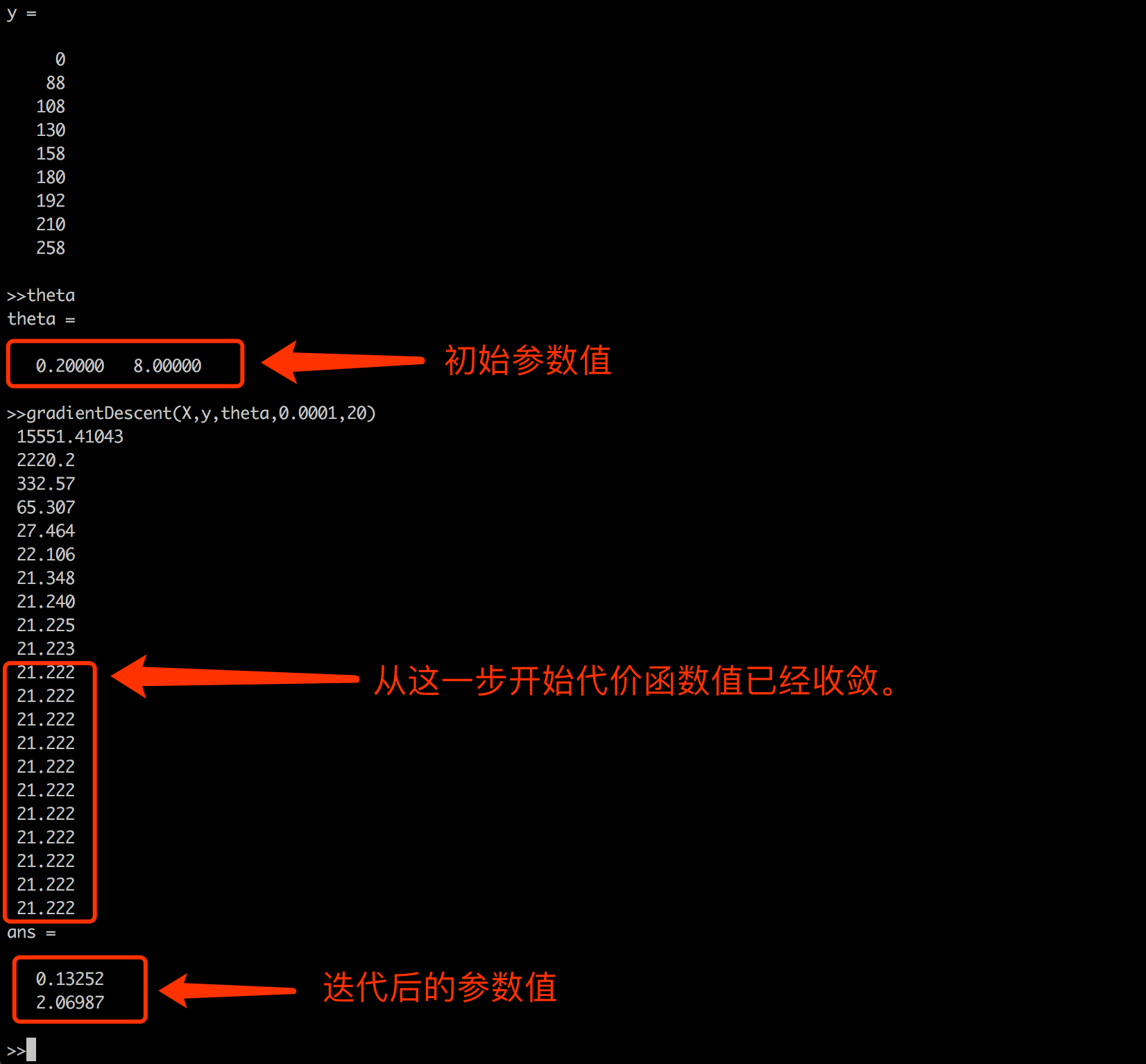
function [theta, J_history] = gradientDescent(X, y, theta, alpha, num_iters) %GRADIENTDESCENT Performs gradient descent to learn theta % theta = GRADIENTDESCENT(X, y, theta, alpha, num_iters) updates theta by % taking num_iters gradient steps with learning rate alpha
% Initialize some useful values m = length(y); % number of training examples J_history = zeros(num_iters, 1);
for iter = 1:num_iters
% ====================== YOUR CODE HERE ====================== % Instructions: Perform a single gradient step on the parameter vector % theta. % % Hint: While debugging, it can be useful to print out the values % of the cost function (computeCost) and gradient here. %