POP(Procedure Oriented Programming) 面向过程编程;OOP(Object Oriented Programming) 面向对象编程;AOP(Aspect Oriented Programming) 面向切面编程。这三组单词代表了三种不同的编程思想,今天我们就一起来研究一下它们具体的含义吧。
POP and OOP 记得刚开始学习 C 语言的时候,老师给我们布置了一个作业,写一个运行在 DOS 窗口的简易学生信息系统。当时也没想太多,就一门心思想着怎么才能实现功能。代码如下所示
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 #include<stdio.h> #include<stdlib.h> #define MAX 20 typedef struct student { long int sno; //学号 int sage; //年龄 char sname[MAX]; //姓名 char sclass[MAX]; //班级 struct student *next; //结构体指针 }student; student *head; //链表的头指针(全局变量) //提前声明接下来将会用到的函数。 void menu(); void toAdd(); void toModify(); void toDelete(); void toSearch(); void toOutput(); void toReadData(); void toSaveData(); void main() { int n = -1; //作为接受用户输入的操作指令的变量。 head = (student *)malloc(sizeof(struct student)); //程序中链表的形式为带有头结点的形式。 head->next = NULL; toReadData(); //当程序开始运行后,toReadData() 函数中把所有的学生信息数据以单向链表的形式读入到内存当中。 menu(); while(n) //具体实现。 { printf("输入(0-5)进行操作:\n"); scanf("%d", &n); while(n<0 || n>5) { printf("错误,输入(0-5)进行操作:\n"); scanf("%d", &n); } switch(n) { case 1: toAdd(); break; case 2: toDelete(); break; case 3: toSearch(); break; case 4: toModify(); break; case 5: toOutput(); break; case 0: printf("谢谢使用!\n"); exit(0); break; default: printf("错误!"); } } } void menu() //菜单函数,用来提示用户进行操作。 { printf("----~~~~----~~~~----~~~~----~~~~----~~~~----~~~~----~~~~----~~~~----~~~~----~~~~"); printf(" ~~~~----~~~~----~~~~----~~~~----~~~~----~~~~\n"); printf(" ---- 欢迎来到学生信息管理系统 ----\n"); printf(" ~~~~ ~~~~\n"); printf(" ----~~~~----~~~~----~~~~----~~~~----~~~~----\n"); printf(" ~~~~----~~~~----~~~~----~~~~----~~~~----~~~~\n"); printf(" ---- 操作 示例: ----\n"); printf(" ~~~~ 1. 注册 ~~~~\n"); printf(" ---- 2. 删除 ----\n"); printf(" ~~~~ 3. 寻找 ~~~~\n"); printf(" ---- 4. 修改 ----\n"); printf(" ~~~~ 5. 概览 ~~~~\n"); printf(" ---- 0. 退出 ----\n"); printf(" ~~~~----~~~~----~~~~----~~~~----~~~~----~~~~\n"); } void toAdd() //新增学生。 { ... } void toModify() //修改学生的信息。 { ... } void toDelete() //删除学生。 { ... } void toSearch() //查询学生信息。 { ... } void toOutput() //输出全部学生的信息。 { ... } void toReadData() //读取文件。 { ... } void toSaveData() //写入文件。 { ... }
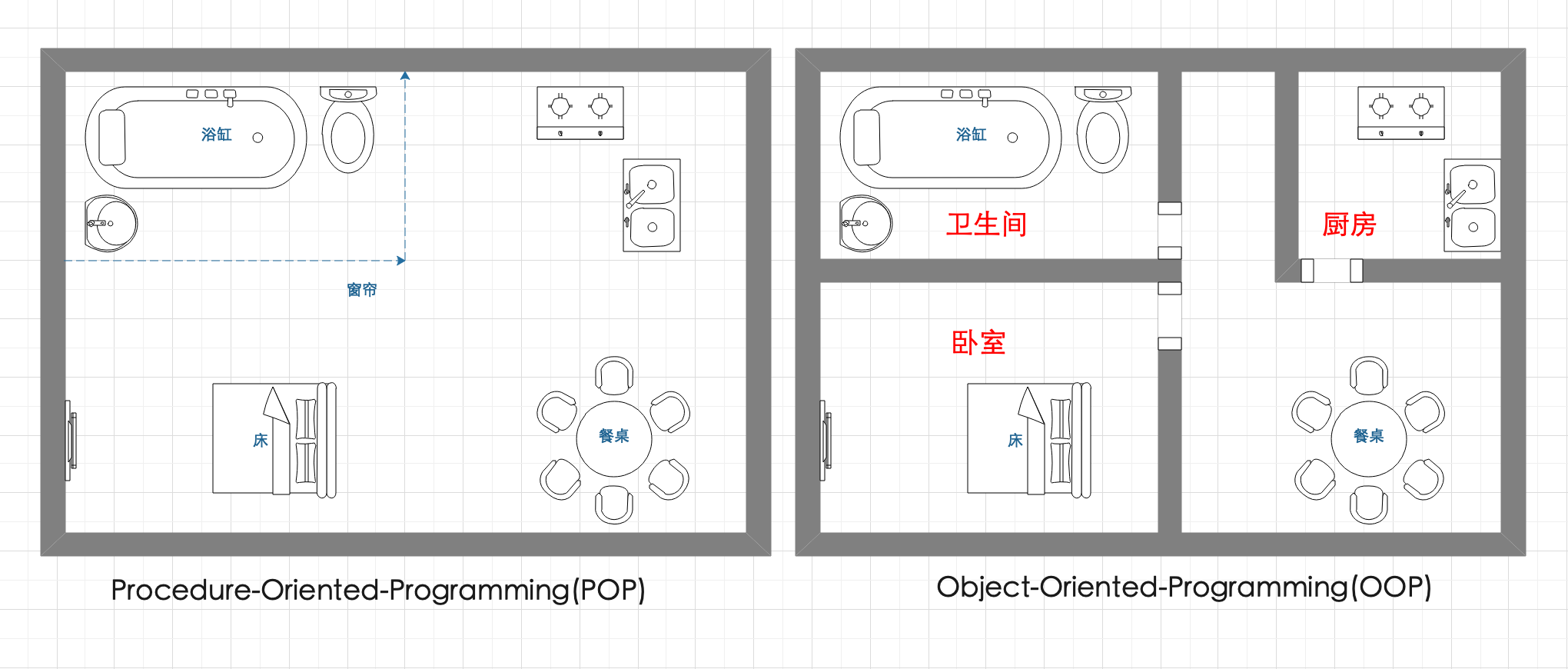
上面的这个程序充分体现了 POP 的思想,即以功能为中心来思考和组织程序。注重的是数据加工和处理的过程,说白了就是注重功能的实现,效果达到了就行。 而 OOP 则注重封装,强调整体性的概念,以对象为中心,将对象的内部组织和外部环境区分开来。有一个比较贴切的例子如下图所示。
假如我们把程序设计比喻为房子的布局。在一间房子的布局中,需要不同功能的家具和洁具(method),例如马桶、浴缸、洗浴台、燃气灶、水槽、餐桌、床、电视等。POP 的程序设计更注重的是功能的实现(method 是否存在),效果符合预期就好。因此 POP 的程序设计会更倾向于左边的房间布局,各种家具齐备(method 都在),房子也就可以正常居住了。
这对于 OOP 的程序设计来说则是无法忍受的,这样布局下的家具和洁具不仅摆放随意,而且相互之间暴露的几率大大增加。 为了更优雅的设计,OOP 程序设计采用了右侧的布局。其中设置了许多小房间,每个小房间都有各自的名称和相应功能(在 Java 语言中这样的小房间被称为 Class)。例如,卫生间是大小解和洗澡梳妆用的,卧室是休息用的,厨房则是做饭用的,每个小房间都各司其职且无需时刻向外界暴露内部的结构,整个房子结构清晰,外界只需要知道有某个房间并使用该房间提供的各项功能即可(method 调用)。
OOP 这样布局的好处是显而易见的。
有利于后期的拓展。
毕竟哪些功能需要添加到哪个小房间,依照分类标准很快就能找到。
可以组织更复杂的程序。
当代码量上来之后,不可能都写在同一个 .c 文件中,需要根据职责拆分成多个 .c 文件,这也符合 单一功能原则 。
OOP and AOP 但随着软件规模的增大,应用的逐渐升级,慢慢地,OOP 也开始暴露出一些问题。
1 2 3 4 5 6 7 8 9 public class A { public void methodA() { //其它业务操作省略... recordLog(); } public void recordLog() { ... } }
1 2 3 4 5 6 7 8 9 public class B { public void methodB() { //其它业务操作省略... recordLog(); } public void recordLog() { ... } }
1 2 3 4 5 6 7 8 9 public class C { public void methodC() { //其它业务操作省略... recordLog(); } public void recordLog() { ... } }
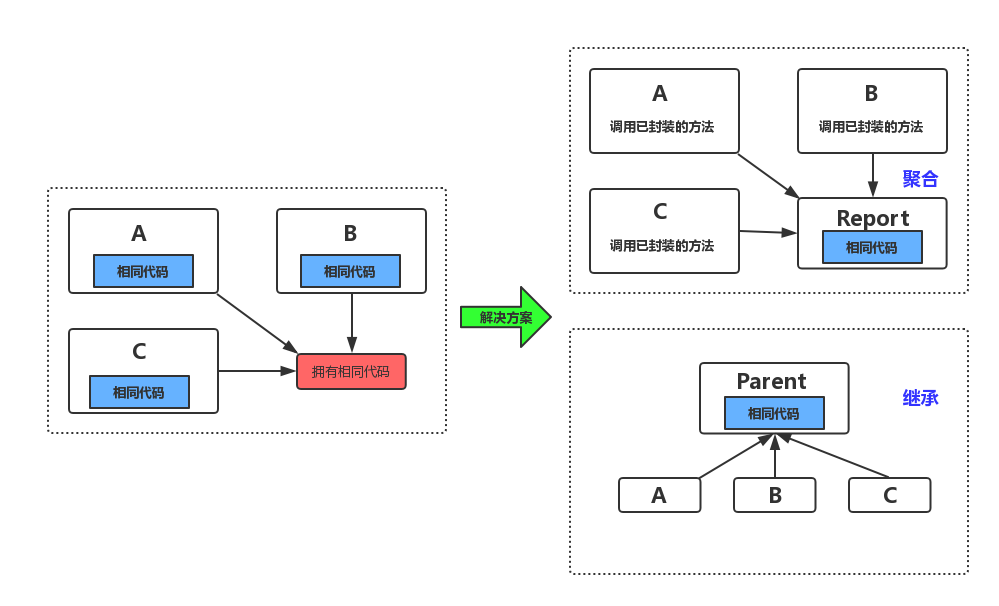
假设存在 A、B、C 三个类,需要在它们的方法被访问时进行日志记录,于是它们的代码中均实现了 recordLog 方法。或许对现在的工程师来说几乎不可能写出如此糟糕的代码,但 OOP 中这样的写法是允许的,而且在 OOP 的初期这样的代码确实存在着。
直到某一天,工程师实在忍受不了『一次修改,到处挖坟』(到处修改 recordLog 方法),才下定决心要解决该问题。为了解决程序间冗余代码的问题,工程师开始使用下面的编码方式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 //A 类 public class A { public void executeA() { //其他业务操作省略... Report.recordLog(args ...); } } //B 类 public class B { public void executeB() { //其他业务操作省略... Report.recordLog(args ...); } } //C 类 public class C { public void executeC() { //其他业务操作省略... Report.recordLog(args ...); } } //recordLog public class Report { public static void recordLog(args ...) { ... } }
采取这样的编码方式,我们欣喜地发现『挖坟问题』被有效地解决了,当 recordLog 方法需要调整时,只需调整 Report 类就行,这就大大降低了软件后期维护的复杂度。而且除了上述的解决方案,还存在一种利用继承来解决的方式(不推荐,应优先使用聚合而不是继承)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 //父类 public class Parent { public void recordLog() { ... } } //A 继承 Parent public class A extends Parent { public void executeA() { //其他业务操作省略... recordLog(); } } //B 继承 Parent public class B extends Parent { public void executeB() { //其他业务操作省略... recordLog(); } } //C 继承 Parent public class C extends Parent { public void executeC() { //其他业务操作省略... recordLog(); } }
事实上,有了上述两种解决方案后,大部分业务场景下的代码冗余问题被有效地解决了,其原理如下图所示。
解决 OOP 代码冗余问题的两种方案
随着软件系统越来越复杂,工程师发现,OOP 又面临新的问题。核心业务中总掺杂着一些它并不关心的通用业务。 如日志记录,权限验证,事务控制,性能检测,错误信息检测等等。
我们来看一个简单例子。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 public class UserServiceImpl implements UserService { private Authorization auth; //权限管理对象 private Log log; //日志操作对象 private UserDao userDao; //核心业务对象 private Transaction transaction; //事务控制对象 @Override public void saveUser() { auth.valid(); //权限验证 log.record(); //日志操作 userDao.saveUser(); //核心业务操作 transaction.commit(); //事务控制 } @Override public void deleteUser() { ... } @Override public void findUser() { ... } }
真正核心业务代码其实就只有一行,但它已经淹没在了众多通用代码之中。 新的问题又来了。
模块混杂。
核心业务模块可能需要兼顾通用业务模块,这些通用业务可能会混乱核心业务的代码。而且当通用业务模块有重大修改时也会影响到核心业务模块,这显然是不合理的。
代码冗余
通用业务模块的代码在许多核心业务模块随处可见,又出现了冗余代码问题。
在新问题面前,前面提及的两种解决方案都已经束手无策了,那么该如何解决呢?事实上我们知道诸如日志、权限、事务、性能监测等业务几乎涉及到了所有的核心业务。如果把这些通用业务的代码直接写入核心业务的代码中就会造成上述的问题,所以工程师希望的是这些通用业务模块可以实现 热插拔 特性 。
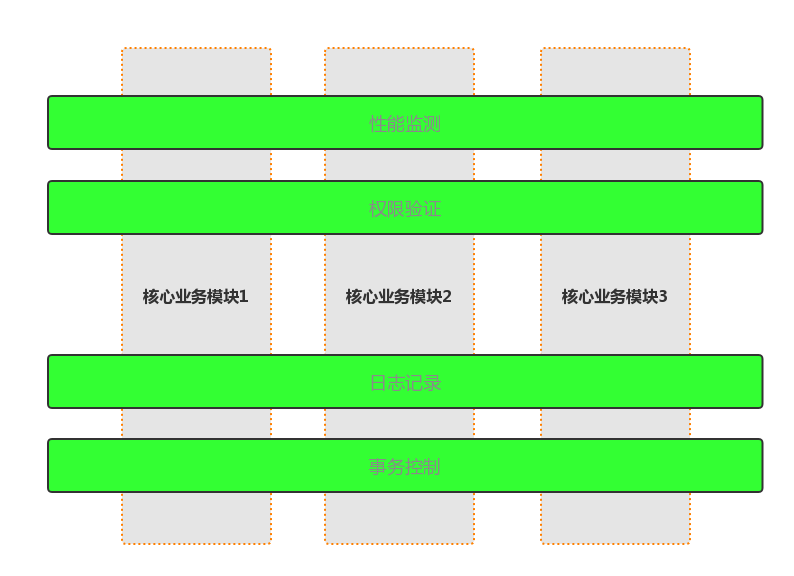
假设现在我们把日志、权限、事务、性能监测等通用业务看作单独的模块(concerns),每个模块都可以在需要它们的时刻被及时运用且无需提前整合到核心模块中,这种形式相当于下图所示。
AOP
从图可以看出,每个关注点与核心业务模块分离,作为单独的功能,进而横切了几个核心业务模块。这样的做的好处是显而易见的——核心模块只需关注自己相关的业务,当需要通用业务(日志,权限,性能监测、事务控制)时,这些通用业务会通过一种特殊的技术自动应用到核心模块中,而这种技术的名称就叫作 AOP。
AOP 的实现技术有多种,其中与 Java 无缝对接的是一种称为 AspectJ 的技术。那么这种 AspectJ 是如何在 Java 中的应用呢?它与 Spring AOP 又有什么关联呢?咱们下次再聊。
小结 无论是 POP OOP 还是 AOP,都只是程序设计的一种指导思想而已,本身并没有什么高低之分。也没有 OOP AOP 就一定比 POP 好用的说法,这需要具体程序具体分析。
引用